"AI 써봤는데 별로던데요?" — 이 말을 하는 분들의 공통점이 있습니다
저는 ChatGPT가 세상에 알려지기 이전부터 AI를 업무에 활용해왔습니다.
사실, 뤼튼 (= 국내 AI 서비스 중 초기부터 서비스된 LLM 기반 플랫폼, 2022년 10월) 을 먼저 접했고, 그 이후
여러 AI 도구들을 직접 써보면서 "이걸 잘만 쓰면 업무 생산성이 완전히 달라지겠다"는 걸 일찌감치 체감했습니다.
개인적으로는 AI활용으로, 업무자동화와 효율화가 매우 빠르게 진행되었고,
그때부터 지금까지 매일 AI 트렌드를 공부하고 있습니다.
그런데 주변에서 AI에 대해 이야기를 나누다 보면,
비판적이고 부정적인 반응을 보이시는 분들에게서 공통된 패턴이 반복된다는 걸 발견했습니다.
제미나이(Google), ChatGPT(OpenAI), 클로드(Anthropic) — 어떤 AI를 쓰시든 상관없이,
심지어 여러 AI를 동시에 쓰시는 분들 중에서도 이 패턴은 똑같이 나타납니다.

AI 활용 능력이 아직 낮은 분들에게서 반복되는 5가지 패턴
AI에게 뭔가 시켰는데 결과가 영 마음에 들지 않아서 "이 부분만 바꿔줘", "아니 그게 아니고…"를 수십 번 반복하다가
결국 "AI는 별 거 없네" 하고 창을 닫으신 적 있으시죠?
그런데 사실, 그건 AI가 나쁜 게 아닙니다. AI를 대하는 방식에 공통적인 패턴이 있고, AI가 텍스트를 처리하는 구조적인 이유에 비밀이 있습니다.
오늘은 그 패턴 5가지와, 왜 첫 질문이 그토록 중요한지 — 원리까지 함께 정리해드릴게요 😊

AI에게 자꾸 화내며 “아니, 그게 아니고…”를 반복하는 내 모습. 여러분도 그러시지 않나요?
PART 1. AI를 잘 못 쓰는 사람들의 5가지 공통 패턴
💡 패턴 1. 결과물이 마음에 안 들어도 첫 질문은 그대로 둔 채 수정만 반복한다
(= 처음 명령이 잘못됐는데, 결과물만 계속 고치려 한다)
첫 번째 결과가 맘에 안 들면 대부분 이렇게 하십니다.
"이 문장만 바꿔줘" "톤만 수정해줘" "아니 존댓말로 하라 했잖아"
"좀 더 전문적으로 써줘" "너무 딱딱해, 부드럽게 해줘"
이렇게 계속 고치다 보면 어느새 10번 넘게 수정 요청을 하고 있는 자신을 발견하게 됩니다.
그런데 처음에 던진 프롬프트 (= AI에게 내리는 명령어, 질문) 자체가 애매했다면 그 뒤의 수정은 전부 땜질에 불과합니다.

예를 들어볼까요?
- AI는 알아서 씁니다. 그런데 사내 공지용인지, 고객 메일용인지, SNS 포스팅용인지 모르죠.
- 결과가 나오면 "이건 너무 격식체야", "고객한테 보내는 거라고 했잖아"라며 수정이 시작됩니다.
- 수정해도 또 마음에 안 들고, 또 수정하고… 결국 30분을 소비합니다.
이게 바로 세션 종속성 (= 한 대화창 안에서 AI가 첫 질문의 틀에 계속 맞추려는 경향) 때문입니다.
처음 방향이 잘못 잡히면 아무리 고쳐도 그 틀 안에서만 맴돌게 됩니다.
결과가 이상하다 싶으면 미련 없이 새 창을 열고, 이번엔 조건을 더 구체적으로 넣어서 다시 시작하는 게 훨씬 빠릅니다.
💡 패턴 2. "AI가 이걸 할 수 있는 건지"를 따지지 않고 무조건 시킨다
(= 가능 여부 확인 없이 반복 요청하다가 지쳐버린다)
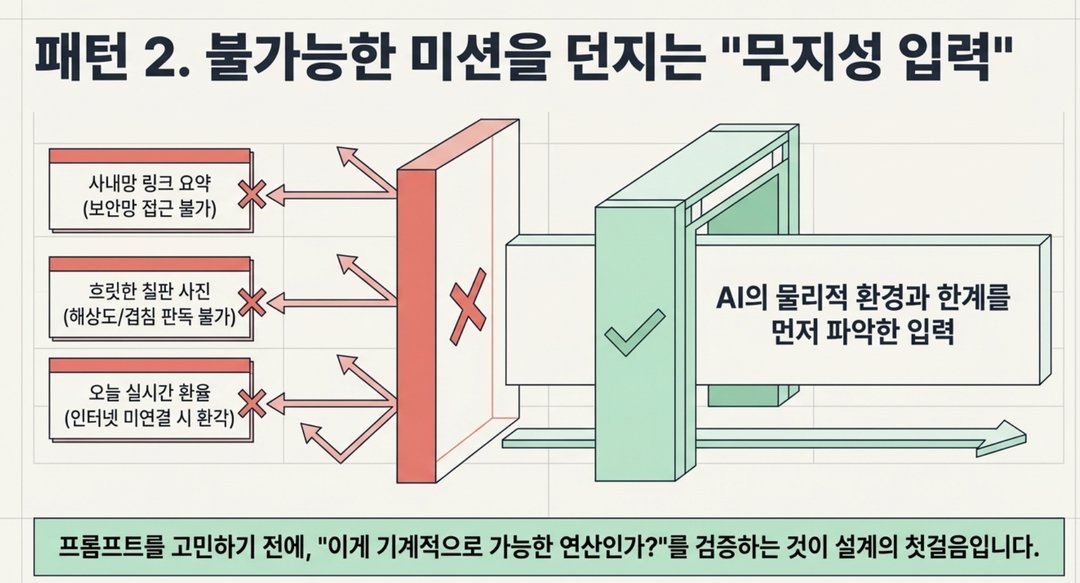
AI도 할 수 있는 일과 없는 일이 분명히 있습니다.
그런데 많은 분들이 이걸 확인하지 않고 계속 시키다가 지쳐버리십니다.
실제로 자주 일어나는 사례들을 보면: 사례 A — 사내 링크를 AI한테 읽어오라고 시키는 경우
"이 사내 공지글 요약해줘" + 링크 붙여넣기
- AI는 회사 보안망 안에 있는 사내에 접근할 수 없습니다.
- 아무리 여러 번 시켜도 결과가 나오지 않습니다.
- 문제는 AI가 아니라, AI가 접근할 수 없는 환경입니다.
사례 B — 흐릿한 사진에서 표 내용을 완벽하게 뽑으라고 하는 경우
스마트폰으로 찍은 회의실 화이트보드 사진을 올리고 "여기 적힌 표 내용 전부 텍스트로 바꿔줘"
- 해상도가 낮거나 글씨가 겹쳐 있으면 AI도 읽을 수 없습니다.
- 이건 사람이 봐도 안 읽히는 사진입니다.
사례 C — AI가 인터넷에 연결이 안 된 상태에서 최신 정보를 요청하는 경우
"오늘 환율이 얼마야?" 또는 "어제 발표된 정부 정책 알려줘"
- 인터넷 검색 기능이 꺼진 상태의 AI는 실시간 정보를 모릅니다.
- 이때 AI가 엉뚱한 숫자를 말하면 그건 AI의 '환각' (= AI가 모르면서 아는 척 답을 지어내는 현상) 입니다.
문서 작업엔 어떤 AI를, 이미지 분석엔 어떤 AI를 쓸지 미리 판단하는 것 자체가 실력입니다.
💡 패턴 3. 젠스파크·마누스 같은 AI 에이전트를 ChatGPT처럼 똑같이 사용한다
(= AI 에이전트 = 스스로 검색하고 판단하고 실행하는 AI인데, 일반 채팅처럼만 쓴다)
요즘 젠스파크(Genspark)나 마누스(Manus) 같은 AI 에이전트 서비스가 핫하죠.
그런데, 써보고 "그냥 ChatGPT랑 똑같잖아요"라고 하시는 분들이 많습니다.
하지만 이 두 가지는 겉모습은 비슷하지만 작동 방식이 다릅니다.

ChatGPT 같은 일반 AI (LLM = 대규모 언어 모델)는 질문을 받으면
- 바로 답을 씁니다. 대화와 텍스트 생성에 강한 도구입니다.
젠스파크·마누스 같은 AI 에이전트 (= 스스로 검색하고 판단하고 단계적으로 실행하는 AI)는 질문을 받으면
- 스스로 검색하고 → 정보를 모으고 → 비교하고 → 정리해서 → 결과를 냅니다.
예를 들어 "국내 친환경 포장재 시장 조사해줘"를 시킨다면:
ChatGPT에게: 한 줄로 던져도 그럭저럭 정리해줍니다. 하지만 최신 정보가 부족하거나 출처가 불분명할 수 있습니다.
에이전트 서비스에 제대로 시키려면: "국내 친환경 포장재 시장 조사
조사 범위: 2023~2025년 국내 시장 포함할 내용: 시장 규모, 주요 기업 3곳, 최신 트렌드
출력 형식: A4 1장 분량 요약표 중간에 출처 링크도 함께 포함"
이렇게 업무 지시서처럼 상세하게 줘야 에이전트가 제대로 작동합니다.
💡 패턴 4. 내가 뭘 원하는지 명확하지 않은 채로 그냥 명령한다
(= 조건 없이 "보고서 써줘"만 하고, 결과가 다르다며 속상해한다)
이게 가장 많이 발생하는 문제입니다. "자료 정리해줘" "보고서 써줘" "발표자료 만들어줘" "전략 짜줘"
이런 식의 명령엔 핵심 조건이 없습니다. AI는 빈칸을 알아서 채우고, 결과를 보면 "내가 원한 건 이게 아닌데?"가 반복됩니다. 결국 패턴 1번으로 다시 돌아가는 악순환이죠.
구체적인 예시를 비교해볼까요?
- AI가 알아서 씁니다. 그런데 경영진 보고용인지 팀 내부용인지, 몇 페이지인지, 수치 중심인지 서술 중심인지 모릅니다. → 결과물이 나와도 "이게 아닌데"가 반복됩니다.
보고 대상: 본부장 이상 경영진 분량: A4 2페이지 이내
형식: 핵심 수치 중심, 표와 글머리표 혼합 톤: 간결하고 격식체
강조할 내용: 매출 목표 달성률, 신규 거래처 확보 건수"
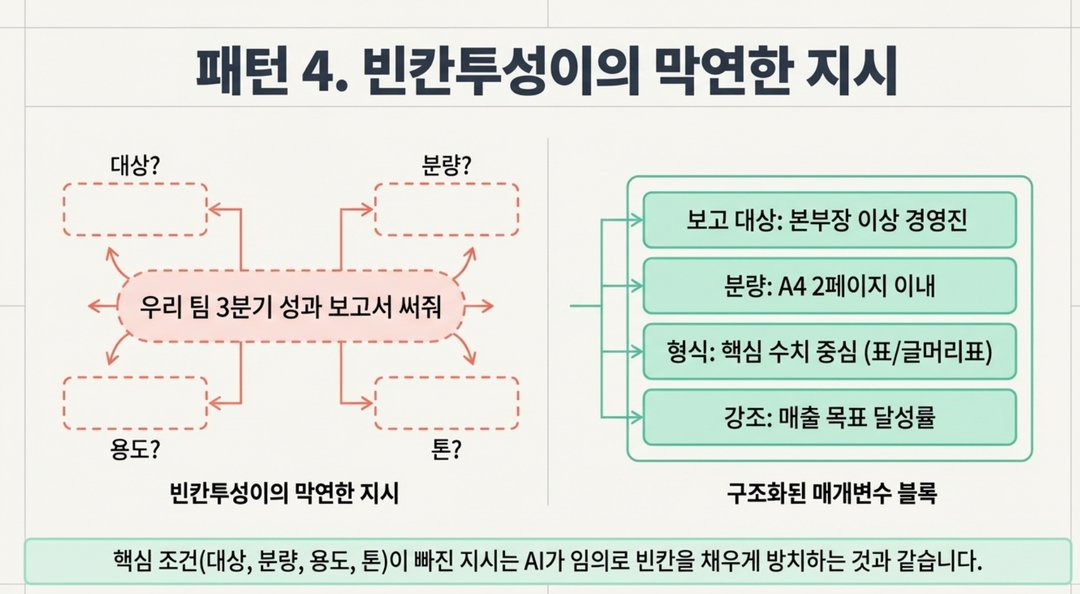
이렇게 쓰면 처음부터 원하는 결과에 훨씬 가까운 답이 나옵니다.
이건 식당에서 "맛있는 거 주세요"만 해놓고 왜 내 취향이 아니냐고 하는 것과 같습니다.
같은 AI를 써도 구체적으로 시키는 사람이 더 좋은 결과를 받는 이유가 바로 여기 있습니다.
💡 패턴 5. 자동화 흐름을 만들어놓고 사람이 확인하는 지점을 지정하지 않는다
(= AI가 알아서 처리하게 두었다가, 오류가 어디서 났는지 나중에야 발견한다)
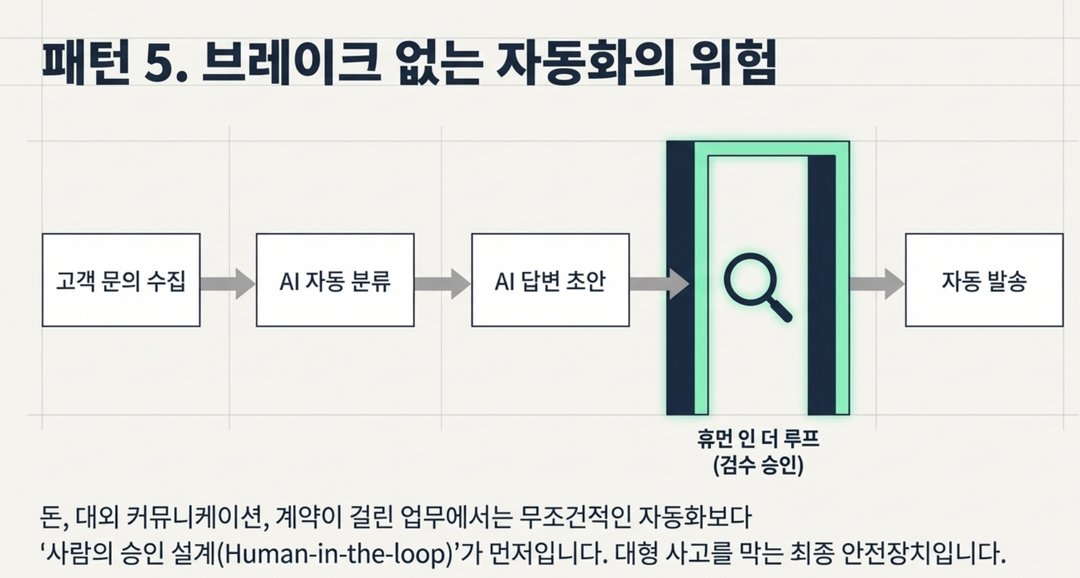
어느 정도 AI를 잘 활용하시는 분들이 자주 놓치는 부분입니다.
예를 들어 이런 흐름을 자동화했다고 해봅시다: 고객 문의 수집 → AI가 분류 → AI가 답변 초안 작성 → 자동 발송
얼핏 보면 완벽해 보입니다. 그런데 실제로 이런 일이 생깁니다.
사례 A: AI가 "환불 요청" 문의를 "일반 문의"로 잘못 분류합니다.
- 고객은 엉뚱한 답변을 받고 더 화가 납니다.
- 어느 단계에서 오류가 났는지 찾기가 어렵습니다.
사례 B: AI가 작성한 제안서 초안에 금액이 잘못 들어갔습니다.
- 검토 없이 자동 발송되어 거래처에 나갔습니다.
- 수정 메일을 다시 보내야 하는 상황이 생깁니다.
이걸 막으려면 자동화 흐름 중간에 반드시 휴먼 인 더 루프 (Human-in-the-loop = AI가 처리한 결과를 사람이 검토하고 승인하는 단계) 를 만들어야 합니다.
공장 라인에도 마지막 검수 공정이 있듯, AI 작업 흐름에도 반드시 사람의 확인 지점이 있어야 합니다.
PART 2. 그렇다면 왜 "첫 질문"이 그토록 중요할까요? — AI가 글을 읽는 방법
💡 AI는 우리 인간처럼 문장을 이해하지 않습니다.
많은 분들이 "AI가 내 말을 이해한다"고 생각하시는데, 현재 AI는 문장의 의미를 사람처럼 이해하는 것이 아닙니다.
우리가 쓰는 모든 AI (ChatGPT, 클로드, 제미나이 등) 의 원천 기술은
2017년 구글이 발표한 논문 "Attention Is All You Need" 에서 출발합니다.
이 AI들은 모두 트랜스포머 아키텍처 (= AI가 언어를 처리하는 설계 구조) 기반으로 작동하며, 문장을 이해하는 게 아니라 이렇게 처리합니다.
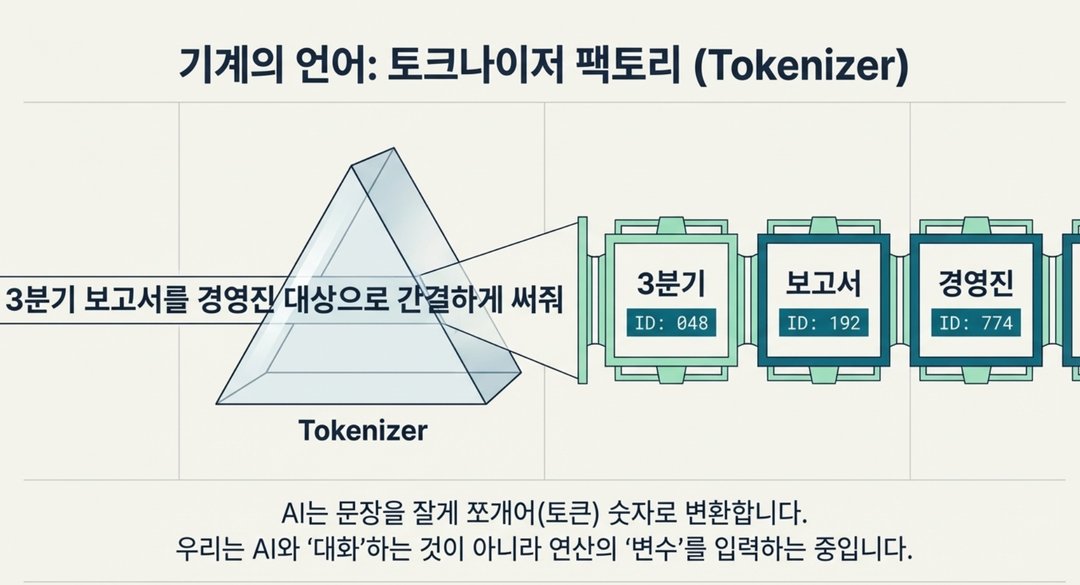
이 쪼개진 조각 하나하나를 토큰 (Token = AI가 처리하는 최소 언어 단위) 이라고 부릅니다.
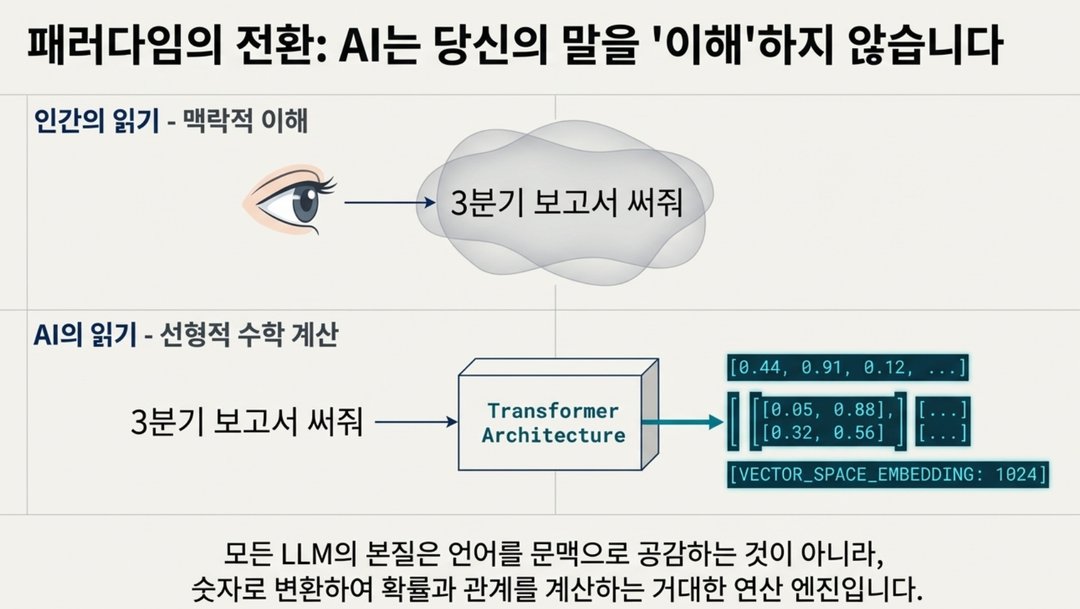
우리 눈에는 이렇게 보이지만: "3분기 보고서를 경영진 대상으로 간결하게 써줘"
AI 눈에는 이렇게 처리됩니다: ["3분기" → 숫자] ["보고서" → 숫자] ["경영진" → 숫자] ["간결하게" → 숫자] …
- 이 숫자들 사이의 관계를 계산해서 → 가장 그럴듯한 문장을 만들어냅니다.
즉, AI는 내 말의 뜻을 '이해'하는 게 아니라 '계산'하는 것입니다.
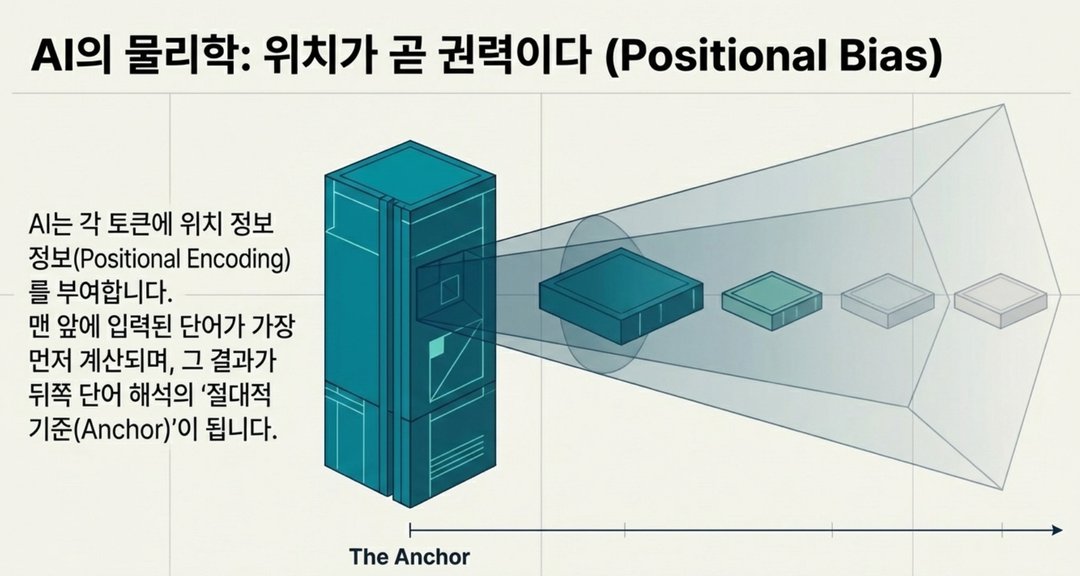
💡 그럼 위치는 왜 중요할까요?
"단어를 쪼개는 거니까 앞뒤 위치는 상관없는 거 아닌가요?"
합리적인 질문입니다. 그런데 여기서 포지션 인코딩 (Position Encoding = 각 토큰이 문장의 몇 번째 위치인지 AI에게 알려주는 정보) 이란 개념이 등장합니다.
수식으로는 이렇습니다: 입력값 = 토큰 (단어 조각) + 위치 정보
쉽게 말하면, AI가 받는 모든 입력에는 "이 단어는 몇 번째"라는 위치 정보가 함께 붙습니다.
그래서 문장을 입력하는 순간 반드시 앞과 뒤가 생기게 됩니다.
2025년 ICML (국제 머신러닝 학회) 에 발표된 연구 "On the Emergence of Position Bias in Transformers" 에서 이를 수학적으로 입증했는데, 핵심만 정리하면 이렇습니다:
실생활 예시로 설명드리겠습니다. 예시 A: "친환경 소재를 사용한 신제품 홍보문구 써줘. 대상은 2030 여성 소비자야."
- AI는 "친환경"이라는 단어를 먼저 기준으로 잡고, 그 기준으로 "2030 여성" 타겟을 해석합니다.
- 결과는 친환경 감성 위주의 문구가 나옵니다.
예시 B: "2030 여성 소비자 대상 신제품 홍보문구 써줘. 소재는 친환경이야."
- AI는 "2030 여성 소비자"를 먼저 기준으로 잡고, 그 다음 친환경을 보조 정보로 해석합니다.
- 결과는 트렌디하고 감각적인 문구에 친환경이 곁들여지는 방향이 나옵니다.
같은 정보인데 순서만 바꿨을 뿐인데 결과가 달라질 수 있다는 것, 느껴지시나요?
이것이 앵커링 효과 (Anchoring = 처음 제시된 정보가 이후 판단의 기준점이 되는 현상) 처럼 작용해서,
첫 프롬프트의 앞부분이 전체 결과의 방향을 결정짓습니다.
PART 3. 그렇다면 어떻게 써야 할까요? — 프롬프트 4가지 원칙
- AI는 "글을 써달라"는 요청을 먼저 처리합니다.
- 길이, 대상, 용도 같은 조건들은 뒤에 붙어 있어서 흐릿하게 반영됩니다.
- 결과물이 나와도 "왜 이렇게 길어?", "왜 어렵게 썼어?" 소리가 나옵니다.
대상: AI를 처음 접하는 일반 직장인 분량: 3줄 이내
톤: 친근하고 쉬운 말투 참고 자료: 아래 내용 기반
- 목적과 조건이 앞에 명확히 정리되면, AI가 처음부터 올바른 기준으로 계산을 시작합니다.
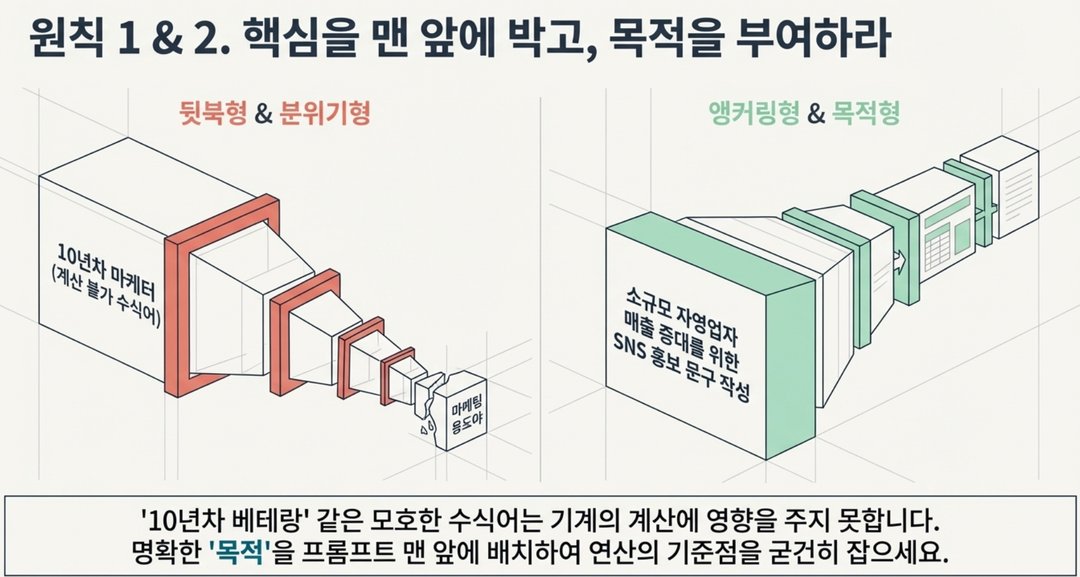
- '10년차', '베테랑'이라는 단어는 AI 계산에 거의 영향을 주지 않습니다.
- AI 입장에서 '10년차'가 어떤 기준인지, 어떤 스타일인지 알 수가 없기 때문입니다.
비유하자면 이렇습니다: 신입사원한테 "당신은 베테랑처럼 일하세요"라고 하면 어떻게 해야 할지 모르겠죠?
"이 자료를 500만원 예산을 가진 소규모 자영업자 설득용으로 써주세요"가 훨씬 명확한 지시입니다.
- 목적과 대상이 명확할수록 AI의 계산 기준이 잡힙니다.
- 특히 최신 AI 모델일수록 모호한 수식어보다 구체적인 목적이 훨씬 잘 먹힙니다.
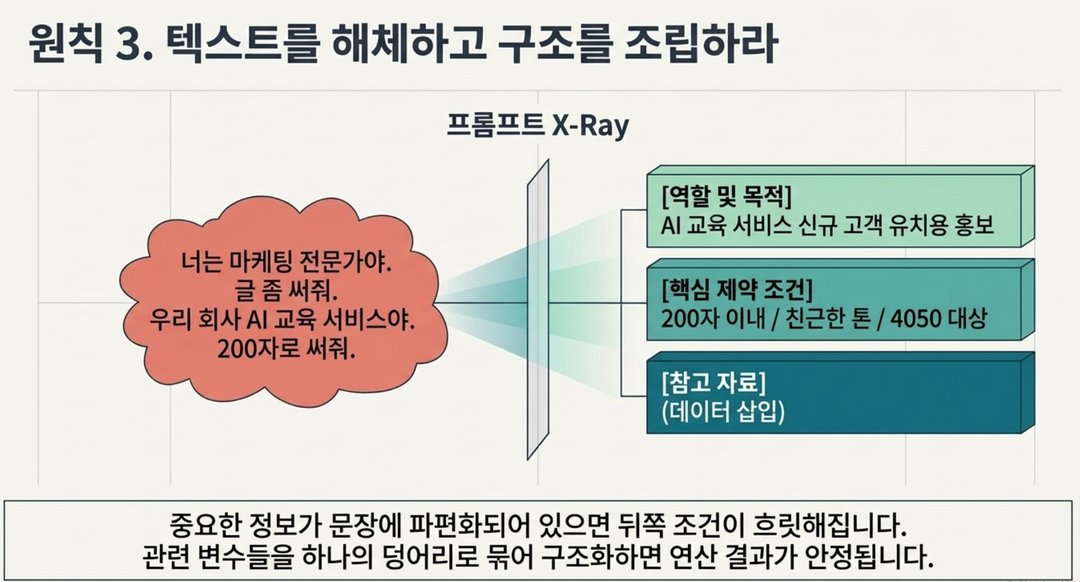
지금 팔려는 건 우리 회사 AI 교육 서비스야. 읽기 편하게 써줘. 200자 정도로 써줘."
- 역할, 목적, 주제, 형식, 분량이 모두 따로따로 떨어져 있습니다.
- AI는 앞쪽 정보를 기준으로 계산하다 보니 뒤쪽 조건인 "200자"나 "읽기 편하게"가 흐릿하게 반영됩니다.
- 결과물이 나와도 뭔가 하나씩 빠진 느낌이 듭니다.
[역할 및 목적] 마케팅 전문가 관점에서, AI 교육 서비스 신규 고객 유치용 홍보 문구 작성
[핵심 제약 조건] 분량: 200자 이내
톤: 쉽고 친근하게 대상: AI를 처음 접하는 40~50대 직장인
[참고 자료] 아래 내용 기반으로 작성
- 같은 정보라도 묶어서 구조화하면 훨씬 안정적인 결과가 나옵니다.
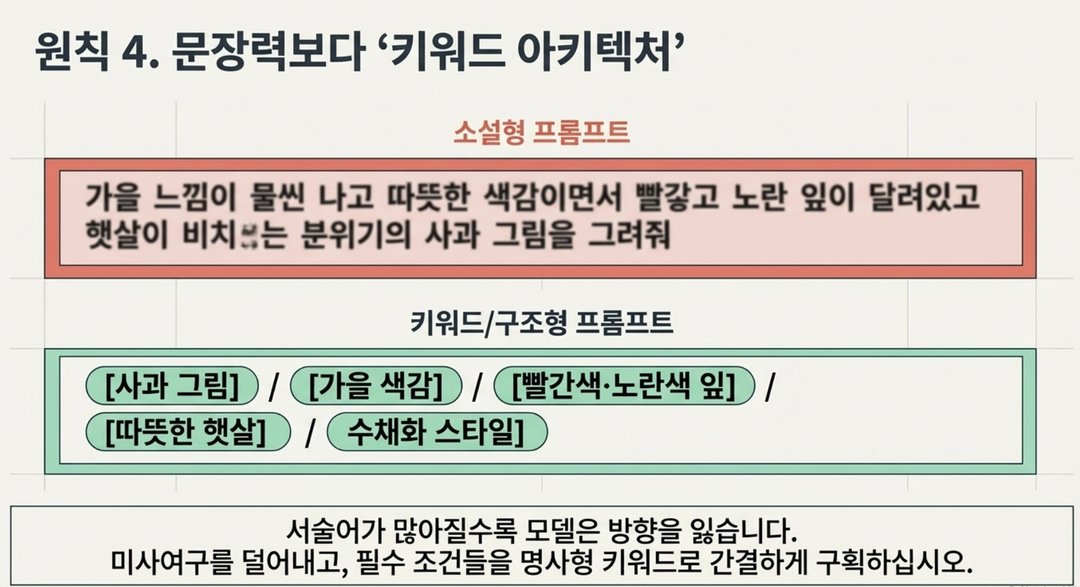
프롬프트가 너무 길거나 설명이 많으면 핵심이 오히려 묻혀버립니다.
특히 이미지 생성 AI (미드저니, DALL-E , 나노바나나 등) 에서 이런 문제가 자주 발생합니다.
- 설명이 너무 많아서 AI가 어디에 집중해야 할지 흔들립니다.
- 핵심 키워드를 앞에, 조건을 간결하게 나열하면 더 원하는 결과가 나옵니다.
일반 텍스트 작업도 마찬가지입니다. 이 구조를 써보세요:
[한 줄 핵심 요약 — 가장 중요한 것] 반드시 지켜야 할 조건 A
반드시 지켜야 할 조건 B [상세 설명 및 배경 정보 — 보조 정보]
- AI가 한 줄 요약을 기준으로 계산을 고정하고, 나머지를 보조 정보로 처리합니다.
마무리하며 😊 AI 활용 실력은 결국 경험에서 나온다고 전문가들은 조언합니다.
그리고 그 경험을 더 빠르게 쌓으려면, AI가 어떤 구조로 동작하는지 기본 원리를 아는 것이 도움이 됩니다.
오늘 내용을 딱 한 줄로 정리하면:
다음번에는 더욱 도움이 될 정보를 가지고 오겠습니다.
참고 문헌 Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention Is All You Need. Advances in Neural Information Processing Systems, 30 (NeurIPS 2017). https://arxiv.org/abs/1706.03762 (PART 2 전체의 토대 — AI가 문장을 토큰으로 쪼개 숫자로 계산한다는 트랜스포머 구조의 원천 논문. "AI는 문장을 이해하는 게 아니라 계산한다"는 설명의 근거)
Press, O., Smith, N. A., & Lewis, M. (2021). Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation. International Conference on Learning Representations (ICLR 2022). https://arxiv.org/abs/2108.12409 (PART 2 — 위치 정보가 AI 계산에 어떻게 반영되는지를 다룬 논문. 포지션 인코딩 개념 설명의 배경 참고 자료)
Wu, X., Wang, Y., Jegelka, S., & Jadbabaie, A. (2025). On the Emergence of Position Bias in Transformers. Proceedings of the 42nd International Conference on Machine Learning (ICML 2025). https://arxiv.org/abs/2502.01951 (PART 2 핵심 근거 — "앞쪽에 쓴 단어가 먼저 계산되어 뒤쪽 해석의 기준이 된다"는 위치 편향을 수학적으로 증명한 논문. PART 3 원칙 1·2의 이론적 배경)
Yi, Z., Zeng, D., Ling, Z., Luo, H., Xu, Z., Liu, W., Luan, J., Cao, W., & Shen, Y. (2025). Attention Basin: Why Contextual Position Matters in Large Language Models. arXiv preprint arXiv:2508.05128. https://arxiv.org/abs/2508.05128 (PART 2 및 PART 3 원칙 3의 실험적 근거 — AI가 입력 순서에서 맨 앞·뒤 내용에 집중하고 중간은 상대적으로 무시하는 현상을 실험으로 증명. "중요한 내용은 앞에, 정보는 흩어놓지 말 것"이라는 실무 조언의 뒷받침)